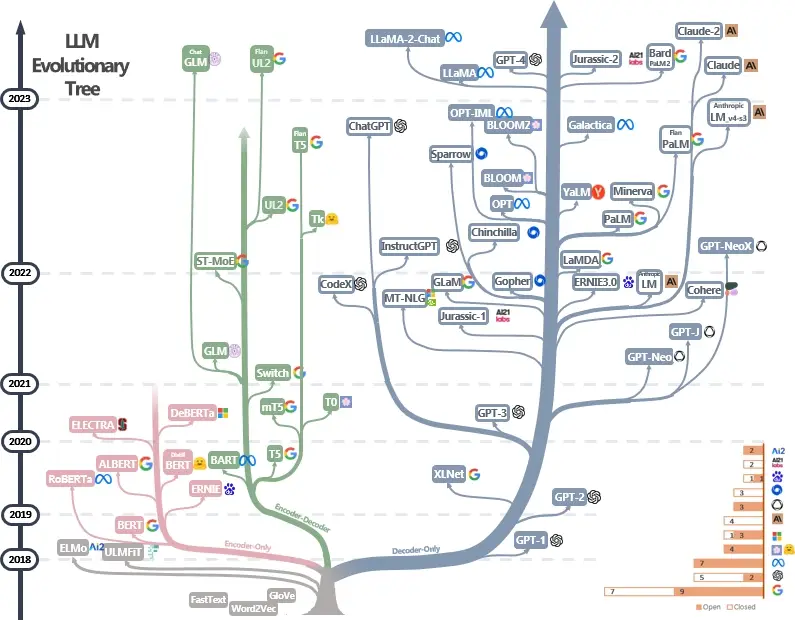
大型语言模型(Large Language Models)是自然语言处理(NLP)领域的一种重要技术,旨在理解和生成人类语言。这些模型通常基于深度学习架构,特别是在大规模数据集上进行训练,以捕捉语言的复杂性和细微差别。

关键特点
- 大规模数据训练: 这些模型通常在包含大量文本的数据集上进行训练,这有助于它们学习丰富的语言知识和复杂的语言结构。
- 深层网络结构: 大型语言模型通常具有深层的神经网络结构,这使它们能够捕捉语言中的复杂模式和长期依赖。
- 高计算资源需求: 由于其庞大的规模和复杂性,这些模型需要显著的计算资源进行训练和推理,通常依赖于 GPU 或其他高性能计算平台。
- 广泛的应用范围: 从文本生成、机器翻译到情感分析和问答系统,大型语言模型在多种 NLP 应用中都发挥着重要作用。
- 持续更新和迭代: 这些模型经常会随着新数据和新技术的出现而更新和迭代,以提高其性能和适应性。
代表性模型
- GPT 系列(如 GPT-3): 由 OpenAI 开发的自回归语言模型,擅长生成连贯和多样化的文本。
- BERT 及其变体(如 RoBERTa): 由 Google 开发的模型,采用双向 Transformer 架构,擅长理解上下文和语义信息。
- T5(Text-To-Text Transfer Transformer): 将各种 NLP 任务统一为文本到文本的格式,提供灵活的应用范围。
- XLNet: 结合了 GPT 的自回归特性和 BERT 的双向上下文理解能力。
- ERNIE、DeBERTa 等: 专注于提升特定类型的语言理解和生成能力,例如对实体和语义关系的理解。
挑战与局限
- 资源消耗: 这些模型的训练和维护需要大量的计算资源和能源。
- 偏见和公平性: 由于训练数据的多样性和复杂性,模型可能会学习并放大数据中的偏见。
- 解释性: 由于模型的复杂性,它们的决策过程往往不透明,难以解释。
尽管存在挑战,大型语言模型在理解和生成自然语言方面取得了显著的进展,成为当今人工智能领域的一个重要研究方向。
涉及核心技术
大型语言模型的开发和应用涉及多个关键技术:
- 深度学习架构: 如 Transformer 架构及其自注意力机制,能够有效捕捉长距离依赖关系。
- 大规模数据集: 高质量和多样性的数据是模型性能的基础。
- 预训练和微调: 两阶段训练方法使模型先学习通用语言知识,再适应特定任务。
- 优化算法: 如 Adam 等,对训练速度和稳定性至关重要。
- 正则化技术: 如 Dropout,用于避免过拟合,提高模型泛化能力。
- 分布式和并行计算: 利用多 GPU/TPU 进行高效的训练和推理。
- 注意力机制: 让模型能够关注输入中最重要的部分。
- 模型压缩与优化: 如量化、剪枝,以减小模型体积,提高推理速度。
这些技术共同构成了大型语言模型的基础,推动着其性能和效率的不断提升。
扩展资源